Cohen's kappa
Introduction#
Cohen's kappa coefficient the amount measure the agreement between two classifiers, like other evaulation metrics, it is a handy tool to evaluate models, it is defined by this formula 👇
This doesn't make a lot of sense, let us understand this better with an example.
The example#
Two machine learning models as admissions officers at a University are going through a list of 100 candidates, who were applying for a grant and it was their decision to accept or decline it.
This is what the results look like 👇
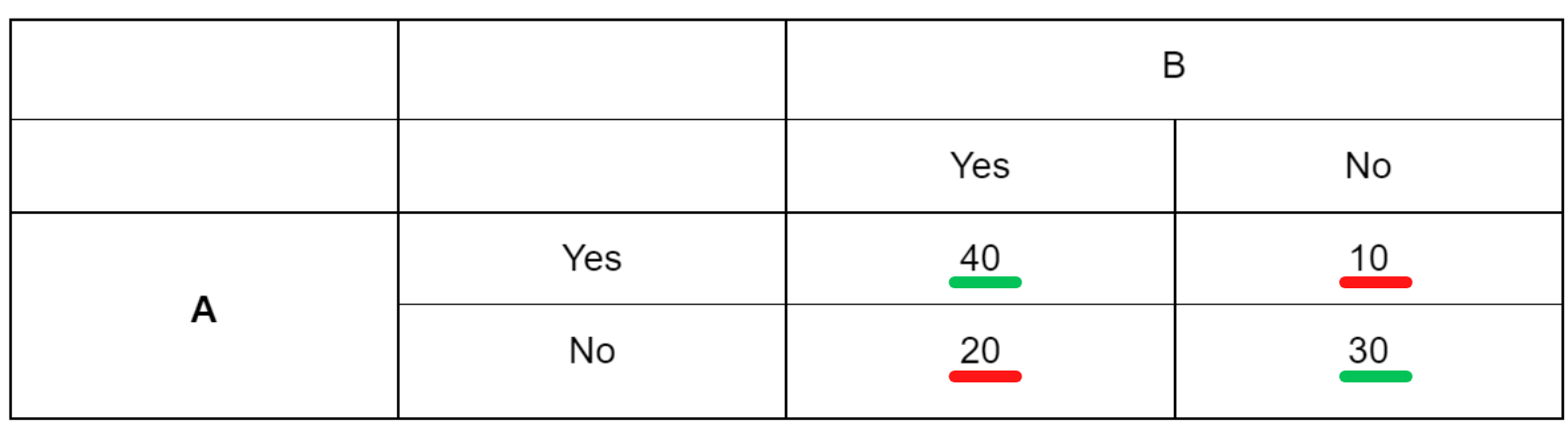
The cases underlined in green are where the admissions officers agree, the red indicates where they don't.
Let's apply the formula that we had before, starting by finding out P0, the probabilty where the 2 admissions officers agree.
P0#
P0 = 0.7 or 70%, what this means is that probabilty that the officers agree is 70%, 7 out of 10 times their decision whether to give a candidate the grant will be the same.
Pe#
Now let's calculate Pe, the probability of random agreement.
Admission's officer 'A' says yes to a candidate 50 out of 100 times, therefore the probabilty that A says yes is 0.5, on the other hand the probability that officer 'B' says yes is 0.6 by this simple calculation.
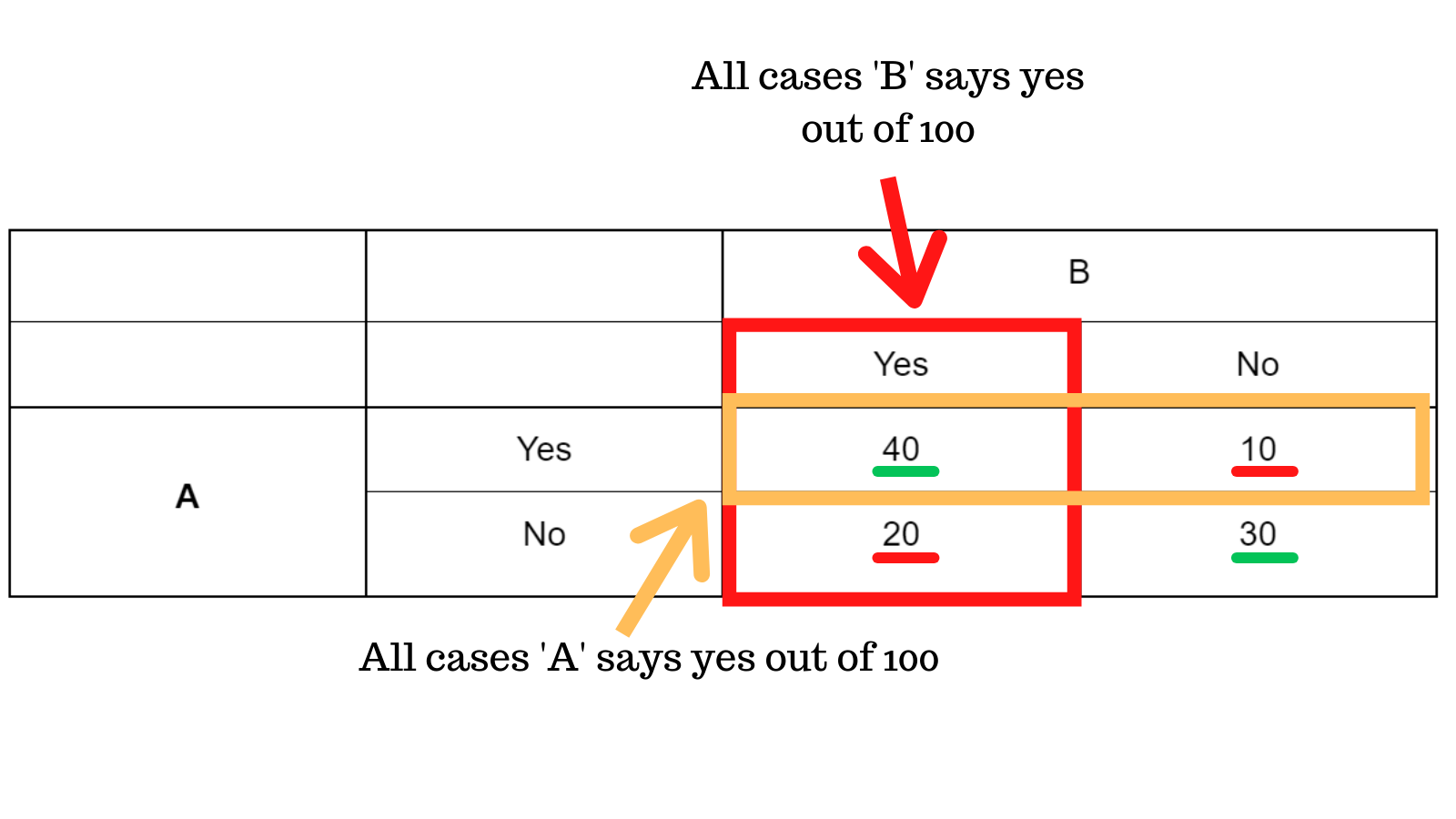
This means that the probability of them both randomly saying yes = 0.5 x 0.6 = 0.3
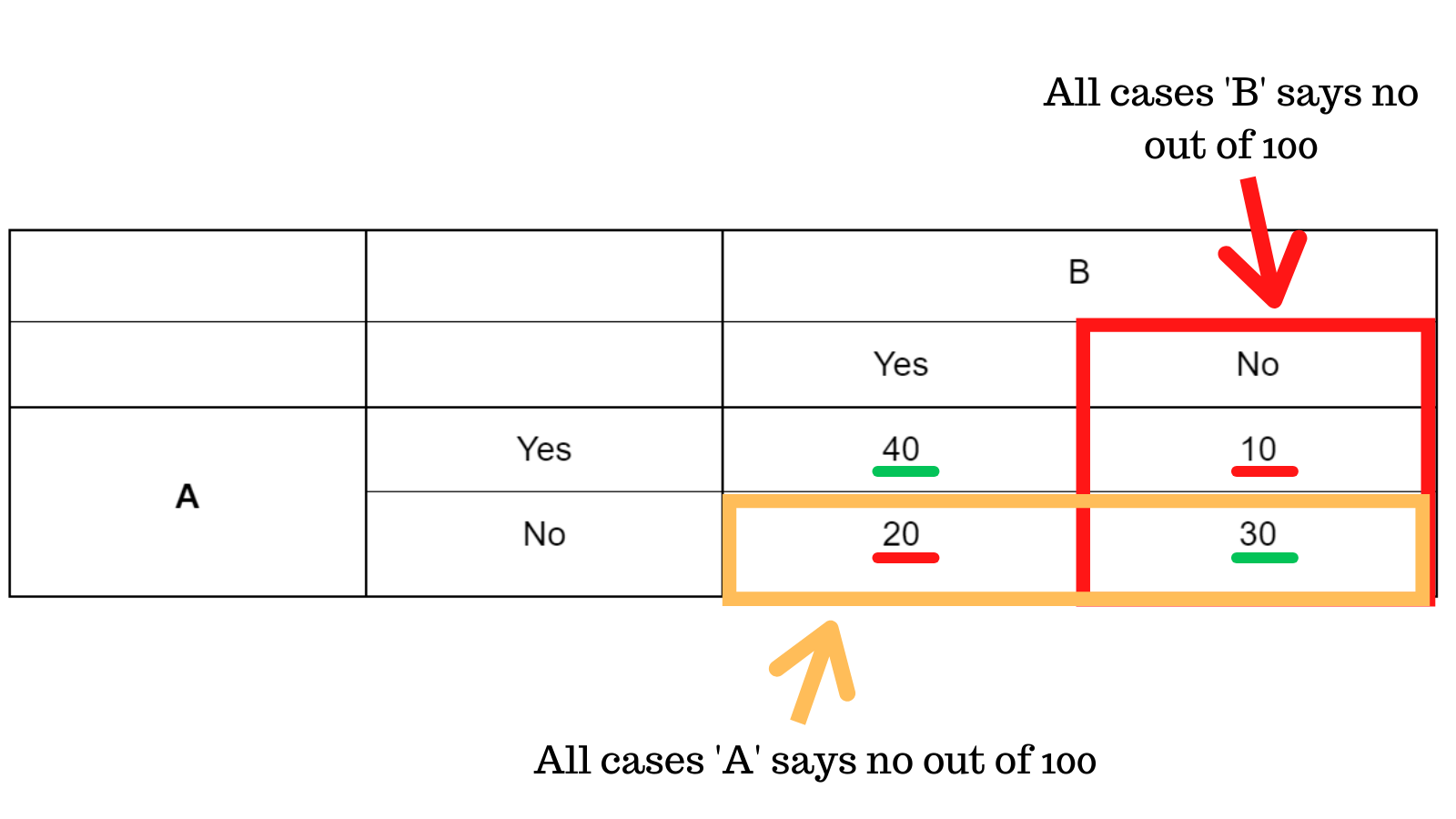
Similarly, applying this in the other case, A says no with a probability of = 0.5 and B with 0.4 which equates 0.5 x 0.4 = 0.2
P0 = 0.7 , Pe = 0.2
Finally, calculating Cohen's Kappa.
Interpretation#
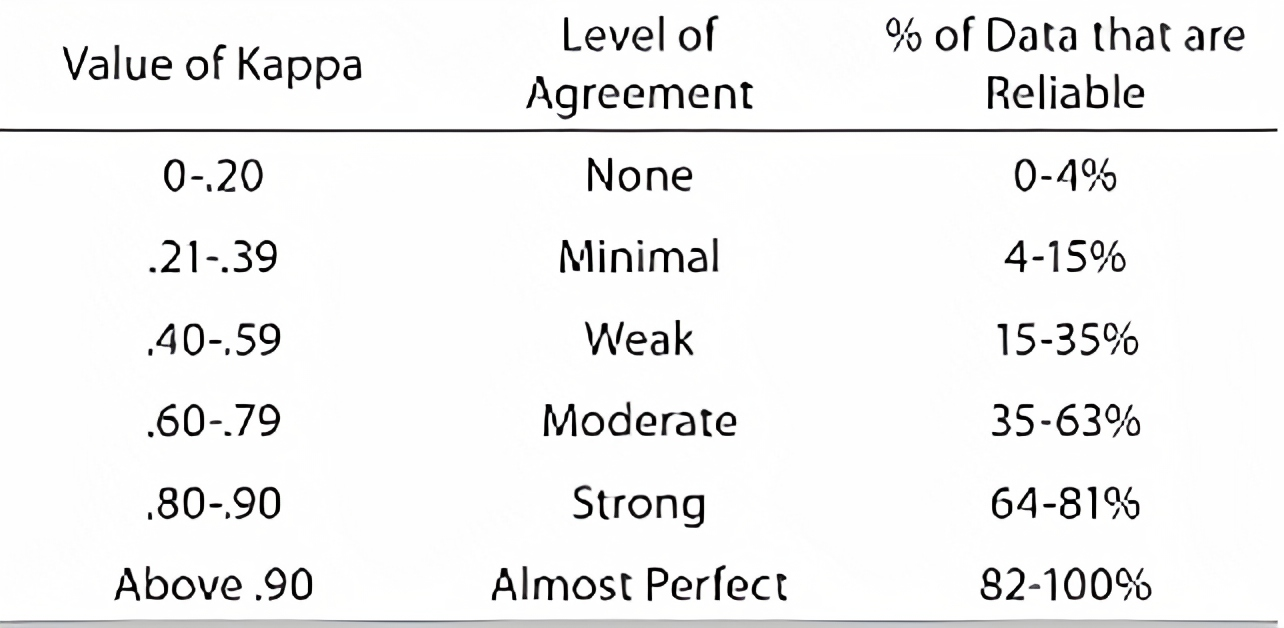
Cohen's kappa is generally used to determine the reliability of data in a dataset, this table is a general rule of thumb that co-relates to the Cohen's Kappa.
It essentially measures how much two models agree with each other.